Автоматически
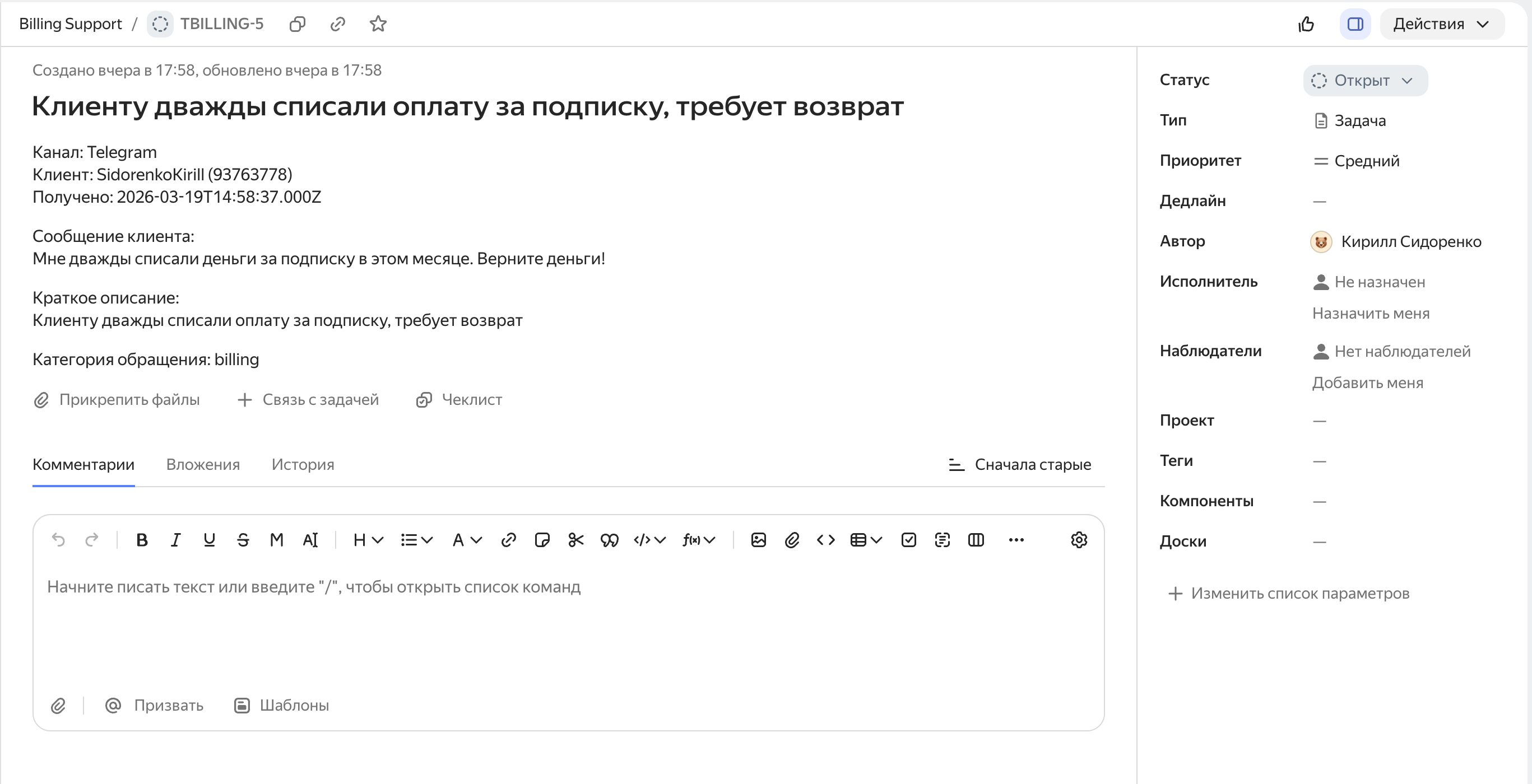
- В трекере сразу создаётся готовая задача
- Команда не тратит время на первичный разбор
Кейс
Автоматизация первичного разбора обращений в поддержке: классификация, приоритизация и маршрутизация за ~3 секунды вместо 3–8 минут ручной работы.
Проблема
Customer support команды в SaaS-компаниях вручную читают, категоризируют, приоритизируют и маршрутизируют каждое входящее обращение. При 200+ тикетах в день это создаёт серьёзные проблемы:
Главный риск — операционный. Критичный инцидент может просидеть в неправильной очереди, пока команда обрабатывает рутинные запросы.
Решение
Автоматически
Ручная проверка
Цепочка работает в n8n: видно, как обращение проходит разбор, где создаётся задача и в каких точках включается ручная проверка.
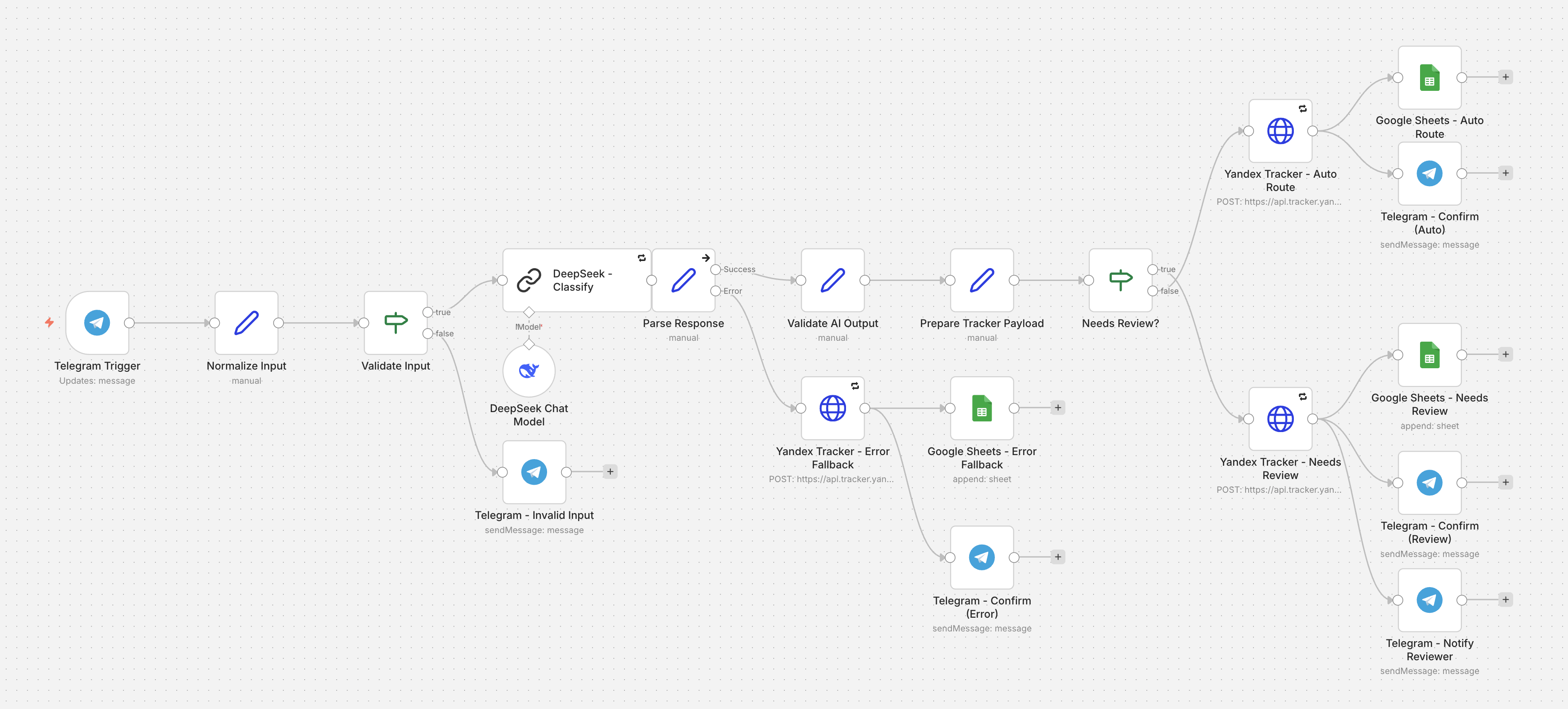
Архитектурные решения
Оркестрация и логика маршрутизации остаются визуальными, редактируемыми и отделёнными от тикетинговой системы. Менеджер видит весь процесс без чтения кода.
Делает маршрутизацию осязаемой: видна финальная очередь, review-очередь и точка передачи команде. Реалистичный support-сетап для российского рынка.
Не как хранилище данных, а как audit log. Мгновенная видимость каждого решения без развёртывания базы данных.
Прямой доступ из России, низкая стоимость ($0.0001/тикет), OpenAI-совместимый API. Достаточное качество для пилотного триажа.
Результаты
| Метрика | Результат | vs. ручной baseline |
|---|---|---|
| Точность категоризации | 92% | +12 п.п. от ~80% вручную |
| Точность маршрутизации | 92% | +12 п.п. |
| Точность триггера review | 94% | надёжный guardrail |
| Точность приоритета | 76% | +30 п.п. через итерацию промпта |
| Время обработки | ~3 сек | vs 3–5 мин вручную |
| Стоимость на тикет | ~$0.0001 | vs $0.50–2 стоимость труда |
Выводы
Поэтому review-слой существует. Confidence полезен, но недостаточен для рискованной автоматизации.
Использование Yandex Tracker вместо только Google Sheets сделало систему реалистичнее. Стало очевидно, как тикет двигается по очередям и зачем n8n существует.
Следующие доказательства качества должны прийти из контролируемого пилота и корректировок ревьюера, а не из спекулятивных изменений промпта.