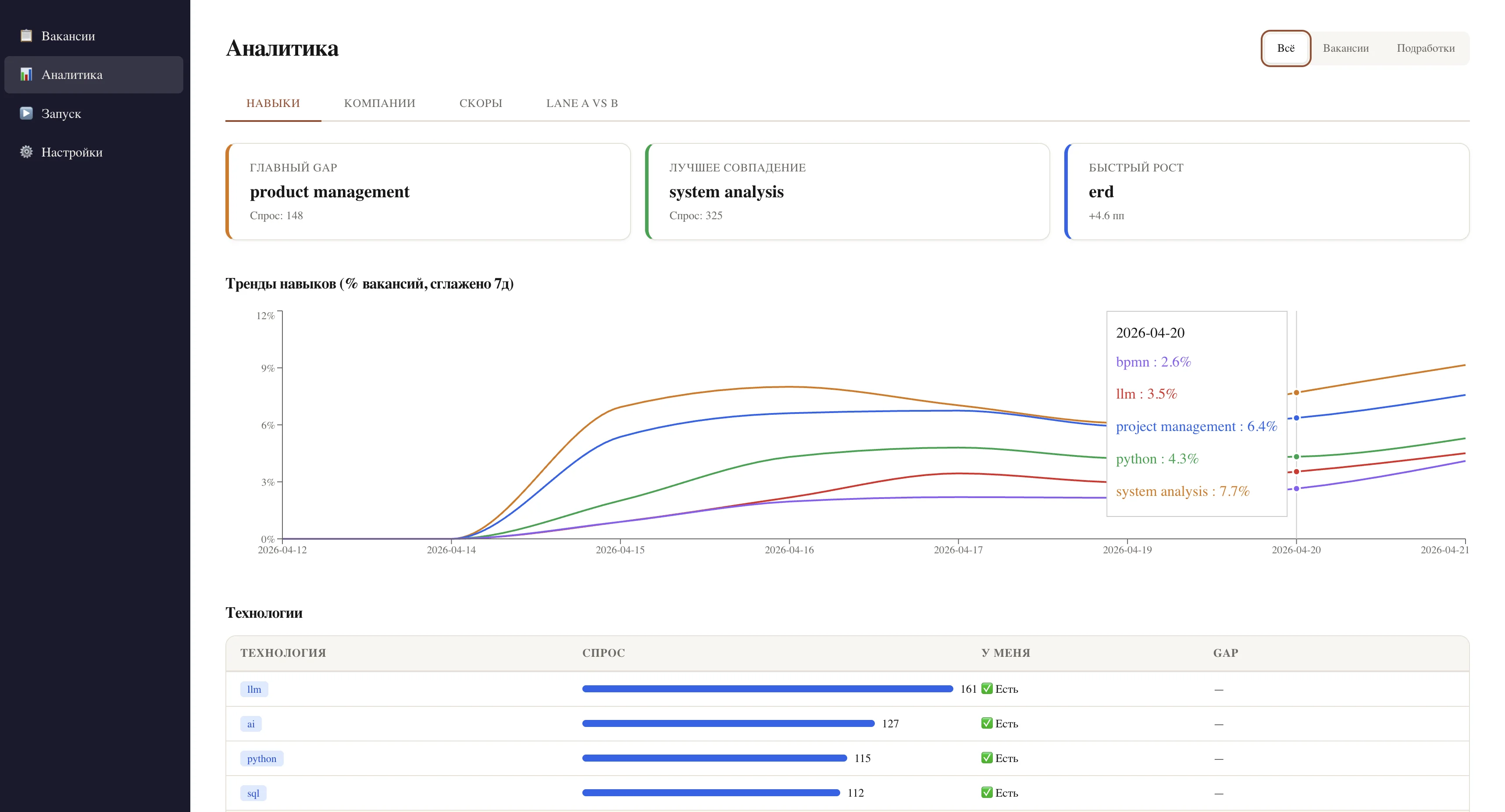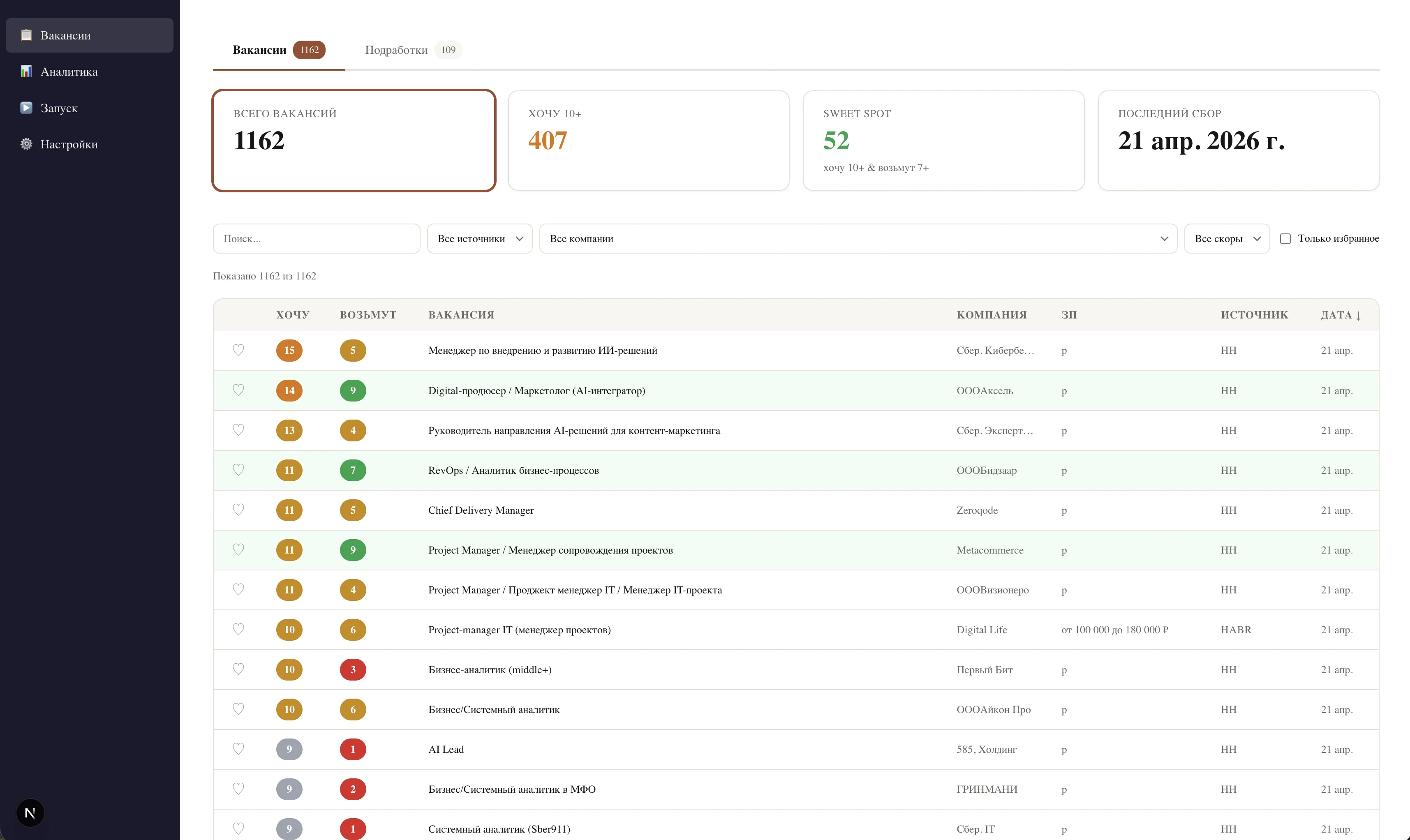
Шум на 70+ источниках
- Десятки career-страниц, hh.ru, Habr, Kwork, fl.ru, Telegram — 300–400 новых листингов в день.
- Ручная сортировка съедает 30+ минут ежедневно и быстро переходит в игнор.
- Хорошие вакансии теряются в потоке «продажника с квотой» и «аккаунт-менеджера в поддержке».